Introduction to FLReconstruct Pipeline Scripts
Though Falaise supplies a set of pipelines for standard reconstruction, it is also possible write your own custom pipeline scripts for use in flreconstruct. These are nothing more than text files marked up using the datatools::multi_properties syntax. Custom pipeline scripts can be run in flreconstruct by passing their path to the -p (or --pipeline) command, for example
or
The major use cases for custom pipelines are to study performance improvements to the current pipelines by tuning parameters or implementing new modules. Here we cover the task of writing a script to build a custom pipeline from the standard modules supplied with Falaise. The more advanced step of writing and using new modules is covered in the Writing FLReconstruct Modules section.
Discovering Available Modules
A list of pipeline modules known to flreconstruct can be obtained using its --help-module-list argument, which will print the module names to stdout:
Details about the purpose of a module and the parameters you can supply to configure it may be obtained by passing the module name as the argument of the --help-module command. This will print out detailed documentation, if it exists:
This information can be used to select suitable modules and configurations for your own pipeline. The following sections provide some simple examples of pipeline scripts.
Implementing Pipeline Scripts
To demonstrate the basic syntax and structure of an flreconstruct pipeline script, the following sections build up functionality from single modules up to using a chain of plugin modules.
Trivial Pipeline
If you do not supply a pipeline script to flreconstruct, it will run a dumb pipeline that simple dumps each event to stdout.
We can reproduce this behaviour using the following simple script to configure the pipeline as a single module:
The script is formatted as a datatools::multi_properties ASCII file. Note the comments, especially:
- The required presence of the
@key_labeland@meta_labelmulti_properties flags - The module constituting the pipeline must have the
namekey set topipeline. FLReconstruct will use this to build the pipeline.
To try this out, copy the above text into a file, e.g. trivial_pipeline.txt and run flreconstruct with it:
You should see the same output as the default case.
Creating a Chained Pipeline
A pipeline with one module isn't very useful! In most cases we want to plug together a sequence of modules, each performing a well defined task on the event data.
Falaise supplies a special chain_module for chaining several modules together. We can reproduce the same default dump behaviour using a chain_module in a pipeline script as follows
Here, the modules key of the pipeline module takes a list of modules that will form the chain_module. To try this out, copy the above text into a file, e.g. single_chain_pipeline.txt and run flreconstruct with it:
You should see the same output as the default case.
Multi-Module Pipeline
A full chain pipeline can chain together 1 < N < X number of modules. The previous example showed the basic construct of a chained pipeline with a single module. We can of course go further and add further module to the pipeline. For example, we can chain two dump modules together. To distinguish these, we configure the modules to have different title and indent parameters.
The order in which the modules are processed is determined by the order in which you list them in the modules key of the dpp::chain_module configuration.
To try this out, copy the above text into a file, e.g. multi_chain_pipeline.txt and run flreconstruct with it:
Try swapping the order of the modules to see what happens, and also try adding further dump modules to the pipeline to experiment with the sequence.
Using Plugin Modules
Falaise supplies several modules as plugins, that is, functionality loaded into flreconstruct after it starts running.
Going Further
You can also write your own modules in C++ and plug them into the pipeline to provide additional functionality. The proceedure for writing and using new modules is covered in several stages, beginning with a simple example.
Detailed Syntax Guide
Basic Script Syntax
FLreconstruct scripts use the datatools::multi_properties format from Bayeux. The script must begin with a mandatory header:
The '#@description' line is optional but highly recommended.
Comments can be placed at any point in the script. Just prepend a sharp ('#') symbol to any comment line. You may also prepend a comment at the end of a line:
Note that lines starting with ‘’#‘’ are generally special meta-comments with embedded commands. They should not be considered as comments. As a matter of rule, the use of lines starting with '#@' is reserved for system use.
After the header, the script contains sections. A section starts with a section definition line with two identifiers:
- the name of the section,
- the type of the section (in
flreconstructscripts it must be"flreconstruct::section").
The syntax is:
The section body uses the datatools::properties format from Bayeux. After the definition line, a short description may be optionally provided thanks to the '#@config' meta-comment:
Then comes the section body which consists in a list of parameter setting directives. The format is:
where NAME is the identifier for the parameter, TYPE is its type and VALUE the selected value for this parameter. Some parameters may use an optional DECORATOR which gives additional information about the parameter's type or processing. Again, the #@description line is optional, but recommended. Example:
How to run a mock calibration on simulated events
When we generate simulated events with FLSimulate, the so-called SD bank contains only raw information about truth calorimeter and tracker hits. In order to be able to reconstruct and analyze the events, we must apply a calibration procedure. This calibration procedure consists of determining physics/geometrical observables associated to hits : deposited energy, particle times of flight, hit positions in the geometry model and so on.
The so-called mock calibration computes the calibrated data associated to raw simulated data.
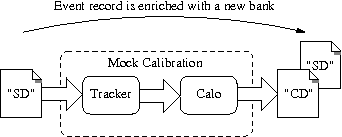
The mock calibration consists of:
- Tracker hits: compute the drift radius and longitudinal position along the anode wire of the Geiger avalanche (and associated uncertainties).
- Calorimeter hits: compute the total energy deposit in the scintillator block and the reference time when the particles first interacted with the block (and associated uncertainties).
A new CD bank holding these data is added in the event record, alongside the raw SD bank.
To see this processing in action, we first prepare a set of 10 simulated events (using the default simulation setup), using the following simu.conf script for FLSimulate:
and run:
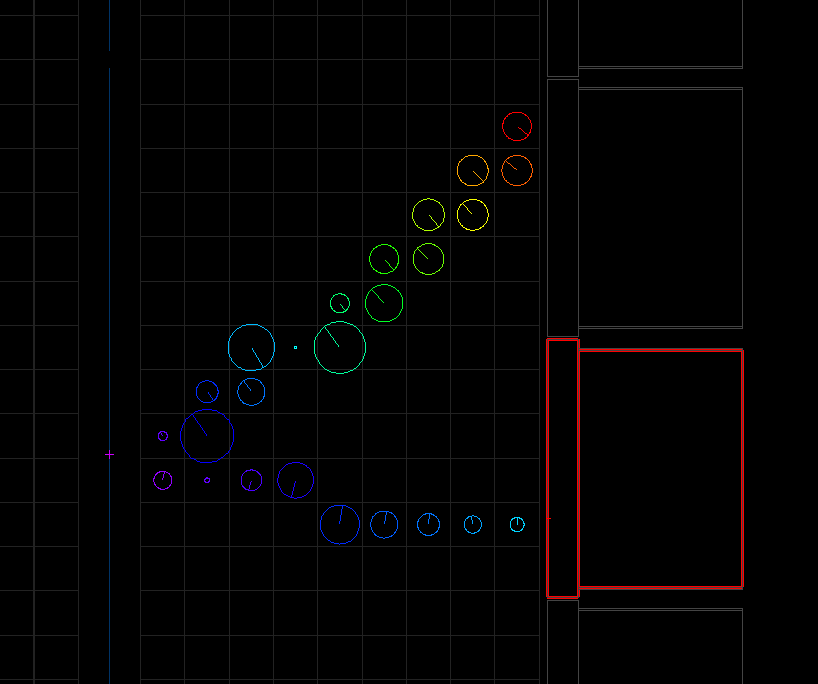
The resulting example.brio file can be opened with the flvisualize application. We can visualize the first event where we will see any raw tracker/calorimeter hits, as well as the position of the decay vertex (cross on the source foil). An example event is shown below, and your view may differ as by default flsimulate will use different seeds on each run, and the styling/colours may also vary between machines:
To process this data in flreconstruct and apply the mock calibration we create the rec.conf script with a custom pipeline inline module made of three consecutive modules. The first one is responsible of the calibration of the tracker hits. The second one is responsible of the calibration of the calorimeter hits. The last one simply prints the content of the events in the standard output:
We use default settings for each of the CalibrateTracker, CalibrateCalorimeters and Dump modules so the corresponding sections are empty.
We then run:
The use of the Dump module prints the events in the terminal. Here is the first event:
We clearly see that a new CD bank (calibrated data) has been added to the event record. It contains two collections of hits, respectively calorimeter and tracker hits.
The example-cd.brio file output by flreconstruct and the pipeline script may be opened in flvisualize as before. Looking at the first event again, we can see additional rendering and information associated to the CD hits (as before, your output will differ due to different random number seeds used in flsimulate):
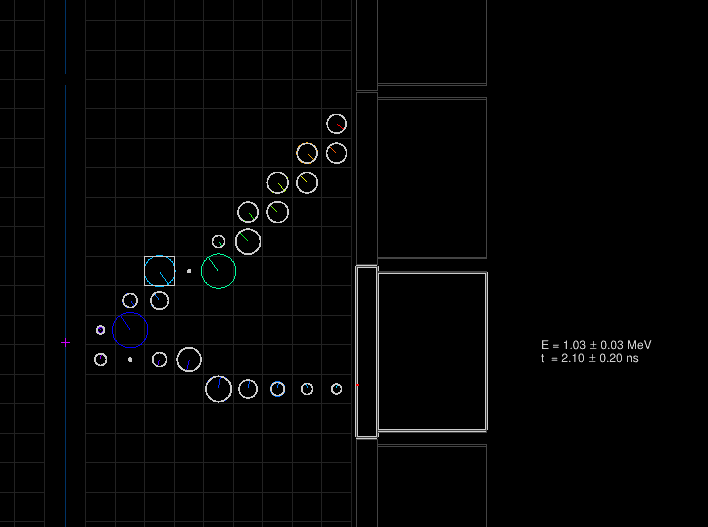
The superimposed white circles on top of the colored ones represent the calibrated tracker hits for which the drift radius and longitudinal position along the anode wire have been computed from the truth hits' timestamps. Here, there is only one calorimeter hit, the total deposited energy in the block and time of entering the scintillator block are also computed (with respect to the arbitrary decay time set by the simulation engine).
How to run a tracking algorithm on simulated events
Now we know how to perform the calibration step, we are interested in the reconstruction of electron tracks in the tracking chamber. For that we need additional processing on top of the CD bank which is now available in the event record.
The reconstruction of tracks associated to charged particles traversing the tracking chamber is a two step procedure:
- first the calibrated Geiger hits are clusterized in tracker clusters, using some special vicinity criteria,
- then a fit is performed on each cluster to compute helix or line segments compatible with the Geiger hits.
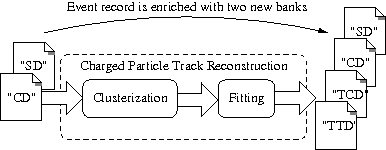
We create a new rec.conf script with a custom pipeline inline module made of five consecutive modules. The first two perform the mock calibration as shown in the previous section. Then we use a new module CATTrackerClusterizer to run the clustering algorithm, followed by the TrackFitting module to run the line/helix fitting on the found clusters. As before, we add a dump module at the end of the pipeline to print each event to standard output.
As we now use modules implemented by dedicated Falaise plugins, we must explicitly provide a flreconstruct.plugins section with the list of plugins that must be dynamically loaded to allow the pipeline to work:
We run:
Now two banks have been added in the event records:
TCD: the tracker clustering data contains the result of the tracker hit clusterization with one or several solutions, each containing a collection of candidate clusters of hit cells. These clusters are used as the input of the track fitting algorithmTTD: the tracker trajectory data contains the result of the tracker fitting with one or several solutions, each containing a collection of candidate fitted tracks (helix or line).
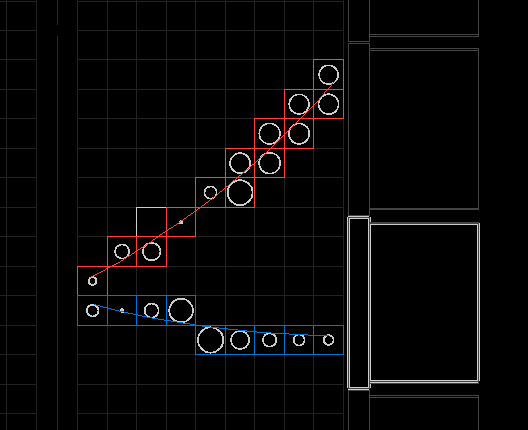
The display shows the best found clusterization/fitting solutions with two clusters of tracker hits (red and blue) and the best associated tracks that have been computed from these clusters. We clearly recognize a two electrons event pattern, but here only one is associated to a calorimeter block.
To do
Document more reconstruction steps:
- charged particle tracking module with extrapolation of vertex, impact points, curvature, track/calorimeter association...
- gamma tracking
- particle identification
Supported sections and parameters in FLReconstruct scripts
The FLReconstruct script contains up to five sections of type flreconstruct::section with the following names:
flreconstruct: this is the system/base section where to set general parameters such as:numberOfEvents: the number of events to be processed from the input (integer, optional, default is:0which means all events will be processed),experimentalSetupUrn: the experimental setup tag (default is:urn:snemo:demonstrator:setup:1.0),
flreconstruct.variantService: this is the variants section where the Bayeux variant service dedicated to the management of variant parameters and configurations is configured. In principle, this section inherits the configuration of the variant service used to generate simulated data.Parameters of interest are:
configUrn: the configuration tag for the variant service associated to the simulation setup (string, optional). If not set, it is automatically resolved from the experiment setup tag.config: the path to the main configuration file for the variant service associated to the simulation setup (string/path, optional). If not set, it is automatically resolved from theconfigUrntag.profileUrn: the configuration tag for the variant profile chosen by the user to perform the simulation (string, optional). If not set, it may be automatically resolved from theconfigUrntag if the variant configuration has a registered default profile.profile: the path to the variant profile chosen by the user to perform the simulation (string/path,optional). If not set, it is automatically resolved from theprofileUrntag or from input metadata.settings: a list of explicit setting for variant parameters chosen by the user to perform the simulation (array of strings, optional). If not set, it is automatically resolved from theprofileUrntag or from input metadata.
flreconstruct.services: this is the services section where explicit configuration for the embedded Bayeux/datatools service manager is defined (by tag or explicit configuration file).Parameters of interest are:
configUrn: the configuration tag for the service manager associated to the data producer setup (string, optional). If not set, it is automatically resolved from the experimental setup tag.config: the path to the main configuration file for the service manager service associated to the reconstrcution setup (string/path, optional). If not set, it is automatically resolved from theconfigUrntag.
flreconstruct.plugins: this is the plugins section where explicit directives are defined to load Falaise plugin libraries which define various types (classes) of processing modules.Parameters of interest are:
plugins: the list of plugins to be loaded.PLUGIN_NAME.directory: the directory from where the plugin dynamic library namedPLUGIN_NAMEshould be loaded (default: "@falaise.plugins:", i.e. the standard location for the installation of Falaise's plugins).
flreconstruct.pipeline: this is the pipeline section where general setup of the reconstruction pipeline is provided.Parameters of interest are:
configUrn: the tag of a registered/official pipeline.config: the main configuration file describing the modules used along the pipeline. If not set, it is automatically resolved from theconfigUrntag.module: the name of the top level pipeline module, chosen from the list of modules defined in the main configuration file (default:"pipeline").
A sample configuration script showing the organisation of the above parameters is shown below. Note that many of the parameters are commented out as they are generally note needed except for advanced use or testing.
The majority of scripts will just use the flreconstruct.plugins and flreconstruct.pipeline sections to select from the set of plugins and pipelines approved by the Calibration and Reconstruction Working Group. Output results from these can be used in the preparation of analyses.
Inline modules
In the case the flreconstruct.pipeline section does not define an explicit pipeline configuration by tag (configUrn) or configuration file path (config), it is possible to provide a list of additional sections which define reconstruction modules. This technique is named the inline pipeline mode. Such a section uses the following format:
where ModuleName is the unique name of the module and ModuleType is the identifier of its registered class type (see below).
This mode should not be used for production runs. It is expected that only official registered pipeline setups are used in such a case, through the configUrn properties in the flreconstruct.pipeline section.
